# 语法 & 示例
# 登录
如果需要更多测试用例,请按照以下步骤获取:
1. 用 Chrome(或 Firefox 等)浏览器中打开 http://apijson.cn/api ,或者 http://apijson.cn 然后点击按钮 [接口 APIAuto 测试] 也行;
2. 点击右上角的“登录”按钮登录;
3. 点击“测试账号”按钮左边第二个按钮,(也就是“-”左边的第一个)获取各种测试用例;
4. 欢迎大家踊跃共享自己的测试用例;
也可以参考 APIAuto 的文档或视频:
https://github.com/TommyLemon/APIAuto
# 查询
为了方便测试,我这里使用的 Chrome 浏览器的 Restlet Client 插件,大家可以根据自己的喜好使用不同的工具测试。
请注意 APIJSONApplication.java 中使用 Tomcat 默认的 8080 端口,如果不小心开着 PC 端的“微信”,8080 端口会被占用,建议改成 8081, 9090 等其它应用程序未占用的端口。
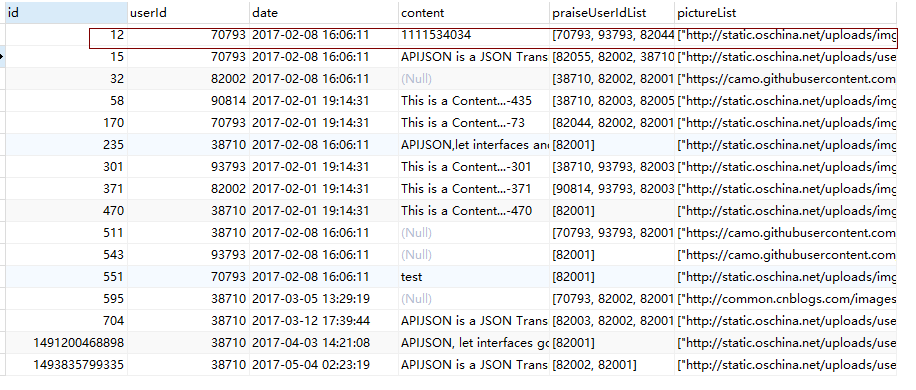
随便找一个上一节中导入的表,比如 Moment 表,我们取其中 ID 为 12 的一条出来看看。下图为数据库中的数据:
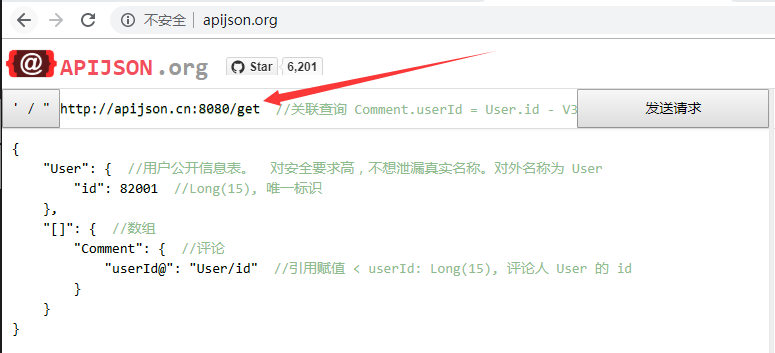
下图所示的连接地址:
http://apijson.cn:8080/get
仅仅是用于演示。如果本地数据库已经配置完成,请在箭头所指方向输入本地数据库的链接地址。例如:
http://localhost:端口号/get
我们接着输入请求的 JSON:
{
"Moment": {
"id": 12
}
}
响应的 JSON:
{
"Moment": {
"content": "1111534034",
"date": "2017-02-08 16:06:11.0",
"id": 12,
"pictureList": [
"http://static.oschina.net/uploads/img/201604/22172508_eGDi.jpg",
"http://static.oschina.net/uploads/img/201604/22172507_rrZ5.jpg"
],
"praiseUserIdList": [70793, 93793, 82001],
"userId": 70793
},
"code": 200,
"msg": "success"
}
# 字段过滤
这里这么多字段,如果我只想要这个 content 字段的信息怎么办?
你可以这样请求:
{
"Moment": {
"id": 12,
"@column": "content"
}
}
响应:
{
"Moment": {
"content": "1111534034"
},
"code": 200,
"msg": "success"
}
@column 表示你要筛选出的字段,如果是多个字段可以这样写"@column":"id,date,content"
# 字段别名
如果想要使用字段的别名应该这样写:"@column":"id,date:time,content:text"
响应:
{
"Moment": {
"text": "1111534034",
"time": "2017-02-08 16:06:11.0",
"id": 12
}
}
这样在返回的数据中 date 字段就变成了 time,content 字段变成了 text。
# 逻辑运算-筛选
如果想要筛选出,ID 在12,15,32中的这三条数据的日期和内容怎么办呢?
请求:
{
"[]": {
"Moment": {
"id{}": [12, 15, 32],
"@column": "id,date,content"
}
}
}
响应:
{
"[]": [
{
"Moment": {
"content": "1111534034",
"date": "2017-02-08 16:06:11.0",
"id": 12
}
},
{
"Moment": {
"content": "APIJSON is a JSON Transmission Structure Protocol…",
"date": "2017-02-08 16:06:11.0",
"id": 15
}
},
{
"Moment": {
"date": "2017-02-08 16:06:11.0",
"id": 32
}
}
],
"code": 200,
"msg": "success"
}
如果所要筛选的数据的是在一定范围内的,比如 ID 是 300 到 400 之间的
你可以这样过滤"id&{}":">=300,<=400"
&的作用是表明后面的两个过滤条件的逻辑关系
(ID >= 300 AND ID <= 500)
现在的逻辑符号一共有三种,&,|,!
默认的逻辑关系是|,也就是说"id|{}":"<=300,>=400"和"id{}":"<=300,>=400"等价。
!主要用于反选,黑名单之类的
"id!{}":[12,15,32]表示id不在 12,15,32 内的其他数据。
复杂一些,如果多个条件相互组合,可以写多个关于 id 的过滤条件
{
"[]": {
"Moment": {
"id&{}": ">=10,<=40",
"id!{}": [12],
"@column": "id,date,content:text"
}
}
}
比如这里表示 id 在 10 到 40 之间,但是却不包含 12 的数据。
# 模糊查询
{
"[]": {
"Moment": {
"content$": "%APIJSON%",
"@column": "id,date,content:text"
}
}
}
使用方式有多种:
keyword%,以keyword开头的字符串。
%keyword,以keyword结束的字符串。
%keyword%,包含keyword的字符串,如:keyword123、123keyword、123keyword123
%k%e%y%,包含字母k,e,y的字符串
还有几种比较便捷的方式,我们这里如果使用"content~":"keyword"来代替"content$":"%keyword%",同样可以表示包含某字符串。
# 正则匹配
{
"[]": {
"Moment": {
"content?": "^[0-9]+$",
"@column": "id,date,content:text"
}
}
}
正则表达式^[0-9]+$,查询content为纯数字的数据,MySQL 的正则语法 (opens new window)如下:
| 模式 | 描述 |
|---|---|
| ^ | 匹配输入字符串的开始位置。如果设置了 RegExp 对象的 Multiline 属性,^ 也匹配 '\n' 或 '\r' 之后的位置。 |
| $ | 匹配输入字符串的结束位置。如果设置了 RegExp 对象的 Multiline 属性,$ 也匹配 '\n' 或 '\r' 之前的位置。 |
| . | 匹配除 "\n" 之外的任何单个字符。要匹配包括 '\n' 在内的任何字符,请使用象 '[.\n]' 的模式。 |
| [...] | 字符集合。匹配所包含的任意一个字符。例如, '[abc]' 可以匹配 "plain" 中的 'a'。 |
| [^...] | 负值字符集合。匹配未包含的任意字符。例如, '[^abc]' 可以匹配 "plain" 中的'p'。 |
| p1|p2|p3 | 匹配 p1 或 p2 或 p3。例如,'z|food' 能匹配 "z" 或 "food"。'(z|f)ood' 则匹配 "zood" 或 "food"。 |
| * | 匹配前面的子表达式零次或多次。例如,zo* 能匹配 "z" 以及 "zoo"。* 等价于{0,}。 |
| + | 匹配前面的子表达式一次或多次。例如,'zo+' 能匹配 "zo" 以及 "zoo",但不能匹配 "z"。+ 等价于 {1,}。 |
| {n} | n 是一个非负整数。匹配确定的 n 次。例如,'o{2}' 不能匹配 "Bob" 中的 'o',但是能匹配 "food" 中的两个 o。 |
| {n,m} | m 和 n 均为非负整数,其中 n <= m。最少匹配 n 次且最多匹配 m 次。 |
# 列表数据
之前我们看到返回的数据是这样的
{
"Moment": {
"content": "1111534034",
"date": "2017-02-08 16:06:11.0",
"id": 12,
"pictureList": [
"http://static.oschina.net/uploads/img/201604/22172508_eGDi.jpg",
"http://static.oschina.net/uploads/img/201604/22172507_rrZ5.jpg"
],
"praiseUserIdList": [70793, 93793, 82001],
"userId": 70793
},
"code": 200,
"msg": "success"
}
里面的pictureList和praiseUserIdList是数组,这种数据在 Mysql 数据库中是 JSON 数据格式的。
数据库里存储的值是这样的
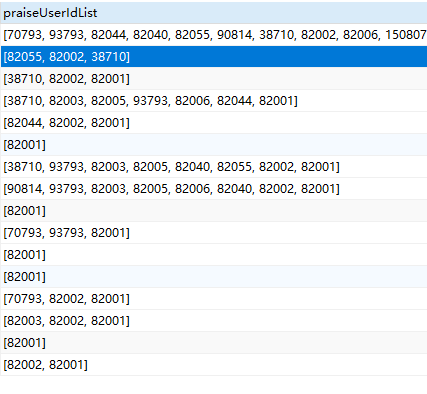
如果我们想过滤出里面有82001的数据,我们应该这样请求
{
"[]": {
"Moment": {
"praiseUserIdList<>": 82001,
"@column": "id,date,content,praiseUserIdList"
}
}
}
结果是类似这样的,为了显示方便剔除了一些数据。
{
"[]": [
{
"Moment": {
"date": "2017-02-08 16:06:11.0",
"id": 32,
"praiseUserIdList": [38710, 82002, 82001]
}
},
{
"Moment": {
"content": "This is a Content...-435",
"date": "2017-02-01 19:14:31.0",
"id": 58,
"praiseUserIdList": [38710, 82003, 82001]
}
},
{
"Moment": {
"content": "https://gss2.bdstatic.com/-fo3dSag_xIb.jpg",
"date": "2018-10-27 17:58:02.0",
"id": 1540634282433,
"praiseUserIdList": [82001]
}
}
],
"code": 200,
"msg": "success"
}
# 分页
对于数量太多的数据,我们很多时候都需要分页操作,这时候我们可以用类似下面这样的请求
{
"[]": {
"Moment": {
"@column": "id,date,content,praiseUserIdList"
},
"page": 0,
"count": 5
}
}
请注意,这里的page和count是放在[]内的属性,而不是Moment对象里。这里count表示每页的数量,page表示第几页,页数从 0 开始算。
也许你想看看这个请求对应的 SQL 语句
SELECT `id`,`date`,`content`,`praiseUserIdList` FROM `thea`.`Moment` LIMIT 5 OFFSET 0
这里thea是我自己的schema的名字,你的可能会有所不同。
如果不想分页的,也提供了一套特殊的查询方式。这种查询方式有三种,请求方式类型这样
{
"[]": {
"Moment": {
"@column": "id,date,content,praiseUserIdList"
},
"query": 2
},
"total@": "/[]/total"
}
这里因为query的值是 2,所有会查询Moment表中所有的数据。如果是 1 的话,则会返回当前表的总数
{ "total": 59, "code": 200, "msg": "success" }
数据库中的数量:

当然,如果你添加了过滤条件,返回的数量就会是你所过滤的数量,比如:
{
"[]": {
"Moment": {
"@column": "id,date,content,praiseUserIdList",
"praiseUserIdList<>": 38710
},
"query": 1
},
"total@": "/[]/total"
}
返回:
{ "total": 12, "code": 200, "msg": "success" }
# 排序
要使用排序的话,这样操作
{
"[]": {
"Moment": {
"@column": "id,date,content,praiseUserIdList",
"praiseUserIdList<>": 38710,
"@order": "date-,id,content+"
}
}
}
"@order":"date-,id,content+"其中,字段的前后顺序表示字段排序的优先级。id和id+是等价的,默认就是升序排列。date-表示将date字段降序排列。
# 关联查询
在讲解关联查询的时候,我们需要先了解下表之间的关系
现在有两张表 USER 和 MOMENT,两张表的关系是下面这样

MOMENT 表示评论,每一条评论会有一个发表评论的用户 USER,所以 MOMENT 表里会有一个 USER 表的外键关联
对于这样的数据关系,我们在查询评论时,很多时候我们会连带着用户一起查处来,这样又如何操作呢
{
"[]": {
"Moment": {
"@column": "id,date,userId",
"id": 12
},
"User": {
"id@": "/Moment/userId",
"@column": "id,name"
}
}
}
这个请求稍微复杂点,首先我们用[]对象表示我们是想查询出一个列表,这个列表包含两个部分Moment和User。
其中Moment是我们想要查询的主要内容,它的写法也和一般查询数据时无异。
User是与Moment相关联的数据,所以查询的时候我们需要用id@来表示他们之间的关联关系
/Moment/userId中,最开始的/相当于是指明了[]的位置,/Moment表示[]对象下的Moemnt对象,/Moment/userId表示Moemnt的userId字段是与User的id关联的。
响应的数据:
{
"[]": [
{
"Moment": {
"date": "2017-02-08 16:06:11.0",
"id": 12,
"userId": 70793
},
"User": {
"id": 70793,
"name": "Strong"
}
}
],
"code": 200,
"msg": "success"
}
# 分组查询
在了解分组查询之前,我们需要先了解下 APIJSON 所支持的函数
| 函数名 | 说明 |
|---|---|
| count | 统计分组下,某字段的个数 |
| sum | 统计分组下,某字段的和 |
| max | 统计分组下,某字段的最大值 |
| min | 统计分组下,某字段的最小值 |
| avg | 统计分组下,某字段的平均值 |
比如,如果只是单纯的查出最大值,这样请求就可以了
{
"[]": {
"Moment": {
"@column": "max(id):maxid"
}
}
}
响应:
{
"[]": [
{
"Moment": {
"maxid": 1541912160047
}
}
],
"code": 200,
"msg": "success"
}
这里maxid是我们取的别名
如果是有分组条件的,那我们需要使用@group
比如,像下面 SALE 表,这张表表示,2018 年 1 月 1 日某公司门下的 3 个店铺(STORE_ID)的营业额(AMT)数据
| ID | STORE_ID | AMT |
|---|---|---|
| 1 | 1 | 100 |
| 2 | 1 | 80 |
| 3 | 2 | 30 |
| 4 | 2 | 100 |
| 5 | 3 | 210 |
如果,我们想要计算出这天每个店铺一共卖了多少,我们通过 APIJSON 可以这样查询
{
"[]": {
"Sale":{
"@column":"store_id;sum(amt):totAmt",
"@group":"store_id"
}
}
}
# 登录
如果没有登录,由于权限的限制,是需要登录的。
登录地址http://127.0.0.1:8080/login,发送请求
{
"phone": "13000038710",
"password": "apijson"
}
账号和密码,可以到apijson_user里面查询
# 测试新增
接口地址:http://localhost:8080/post
我们想新增一条备注时,发送这样的请求
请求
{
"Moment": {
"content": "今天天气不错,到处都是提拉米苏雪",
"userId": 38710
},
"tag": "Moment"
}
tag是我们在request表里面配置的tag字段。
响应
{
"Moment": {
"code": 200,
"count": 1,
"id": 1544520921923,
"msg": "success"
},
"code": 200,
"msg": "success"
}
返回的id是新增的数据的新 id
# 测试修改
接口地址:http://localhost:8080/put
修改备注和新增类似
请求
{
"Moment": {
"id": 1544520921923,
"content": "海洋动物数量减少,如果非吃不可,不点杀也是在保护它们"
},
"tag": "Moment"
}
响应
{
"Moment": {
"code": 200,
"count": 1,
"id": 1544520921923,
"msg": "success"
},
"code": 200,
"msg": "success"
}
如果要对json类型操作的话,这样请求
{
"Moment": {
"id": 1544520921923,
"praiseUserIdList+": [123]
},
"tag": "Moment"
}
这里的praiseUserIdList是一个json类型的字段,在操作之前它是空的[],提交以后它是[123],如果再添加一个 21,则会变成[123,21]
要删除其中的值,把+变成-即可
# 测试删除
接口地址:http://localhost:8080/delete
请求
{
"Moment": {
"id": 1544520921923
},
"tag": "Moment"
}